I’ve just returned from a fantastic Understanding Regular Expressions tutorial given by Damian Conway for FLOSS UK (formerly the UK UNIX Users Group). Damian is a bit of a legend in the Perl community having won the Larry Wall award 3 times, written Perl Best Practices and spent quite a few years working on Perl 6. He is also a thoroughly engaging and very entertaining presenter.
We started the day reviewing how the regular expression engine actually works. Now, I’ve been using regexen for a fair few years now, but I found Damian’s explanation that the regex engine is a mini-language within Perl a much more powerful way to reason about what actually occurs when running a regular expression than the way I’ve been accustomed to conceptually modelling it — as describing the parts of a string I want to match. We looked at a number of examples of regexen and broke them down into state (“railway”) diagrams which help immensely in deconstructing their behaviour. We then looked at the railway diagrams from another angle — as trees. Search trees, of which we do a depth-first ordered traversal. The sort of thing that is the bread and butter of a jobbing computer scientist and suddenly makes regexps seem very straightforward indeed.
Damian talked a little about the design choices in the engine, coming out with what for me was his quote of the day, Perl would rather be fast and wrong that slow and correct
. He talked about the design choice to shy away from optimisations to the engine that could be exponentially slow in some cases, in favour of an engine that was slower in many cases but not disasterously slow in unusual cases.
Perl would rather be fast and wrong than slow and correct
Part of the finite state machine/DSL/tree explanation of Perl’s regexes was “pedagogical facilitation” (white lies) — a simplification to help us reason about our regex, the real situation is a little more complicated, given that our “tree” can contain various branching and looping structures. We also looked at predefined subpatterns (\w\W\d\D) and more interesting post Perl 5.10 ones like \h and the “plausible EOL sequence” \R — shorthand for "\x0D\x0A?|[\x0A-\x0C\x85\x{2028}\x{2029}]" and preferable for humans!
Damian introduced us to his incredible Regexp::Debugger module, which he made frequent use of in his explanations. I’ve not encountered the mopdule before, but I have to say I was very excited when I considerred the hours of time it might have saved me. You should check it out.
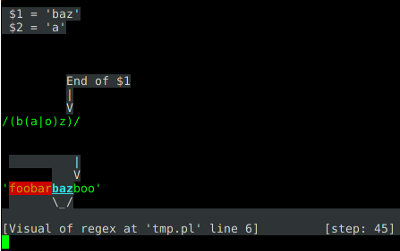
Regexp::Debugger in action
After this overview we moved on to some specifics. Capturing, backreferences and interpolation firstly, then we looked at the new smart matching operator ~~ befoere moving on to substitution, alternative delimiters (hint {} is probably best) and optimisation with qr// and /o. We spent a good amount of time looking at ways to optimise backtracking, the demo code went from having to perform 1109 operations to performing 80-something — an order of magnitude performance increase gained with very little complexity overhead, simply adding (?> ) round our match to avoid unnecessary backtracking and ^ used when we can.
The later parts of the day, we looked in detail at some of the newer and more advanced features available to Perl programmers including deferred subpatterns, named captures and named subpatterns. These Damian brought elegantly back to be relevant to his central theme of regexen as a language within the language Perl tying them back to conceptual territory that is familiar to programmers and not a mystery wrapped in an enigma wrapped in line-noise
.
The worst thing about writing Regexp:: Debugger was not having Regexp:: Debugger to debug it
Reflections and insights gained
I gained a new way of looking at regexen that I’ll definitely be using in my future Perl hacking. Some specific lessons that I drew from the day were
- Regexp::Debugger is seriously cool. Again quoting Damian, "the worst thing about writing Regexp::Debugger was not having Regexp::Debugger to debug it with"
- Using /x is a good idea
- Named captures and named subpatterns rule if you're trying to build a complex recursive regex
- Regexen are just another programming language, once you add in the branching constructs, and programming them can feel just like "normal programming".
- The regex engine is both more stupid and more clever than I had given it credit for.
Thanks to FLOSSUK for organizing the day and to Damian for a thoroughly enlightening and very enjoyable tutorial.